


Por Alberto Morán*
Hoy en día, en determinadas investigaciones científicas, se obtienen cantidades enormes de datos. Sin la ayuda de la tecnología, es casi imposible obtener conclusiones biológicas de estos datos. Así que hemos decidido contaros en el post de hoy algunos ejemplos de investigaciones científicas en las que se generan cantidades ingentes de datos y como el big data ayuda en esos casos.
Lo primero que tenemos que dejar claro es que los que escribimos aquí somo científicos, no expertos en tecnologías de la información, por lo que no profundizaremos mucho en la parte tecnológica.
En lo que respecta a recopilación y tratamiento masivo de datos hay varios términos que usan los aspectos que es frecuente confundir (a nosotros nos pasa). Así, big data, data mining y data science son técnicas distintas y complementarias.
El big data es el proceso de recolección y gestión de grandes volúmenes de datos. Esto incluye su almacenamiento y la búsqueda de patrones repetitivos.
El data mining es el conjunto de técnicas que permiten explorar grandes bases de datos. Nos ayuda a comprender el contenido de una base de datos, filtrarlo, limpiarlo y eliminar todo aquello que no aporta a lo que buscamos. Para ello se utiliza estadística, algoritmos… Nos ayuda a obtener información relevante a partir de los datos.
El data science tiene el objetivo de entender los datos y convertirlos en conocimiento. Pretende exprimir esos datos para sacar conocimiento y patrones que no son obvios. Usa para ello grandes cantidades y varias bases de datos, algunas derivadas de procesos de data mining.
En cualquier caso, en los ejemplos que os vamos a poner, nos vamos a referir de una manera genérica a la obtención y procesamiento de cantidades masivas de datos. La única intención es que os deis cuenta de la cantidad de información que se obtiene hoy en día en ciencia y de cómo necesitamos ayuda para obtener datos, manejarlos y comprenderlos.
GENÓMICA
Una de las áreas de investigación donde inmediatamente pensamos en grandes cantidades de datos es el estudio de los genes. La genómica es el estudio del material genético de los organismos. Lo primero que tenemos que pensar es que nuestro genoma, el conjunto de información que codifica para absolutamente todo lo que somos y que está en el núcleo de nuestras células, está formado por unos 3.000 millones de letras. Variaciones mínimas en esos 3.000 millones de letras provocan variaciones en nuestras características físicas o son las causantes de enfermedades.
Desde hace años, los investigadores se han esforzado en conocer con exactitud la posición de estas letras (nucleótidos), qué cambios de orden de las letras (o sustituciones o “borrado”) de algunas de ellas se asocian con enfermedades, con variantes de enfermedades o incluso con protección frente a ellas. También se han localizado físicamente en nuestros cromosomas, se han situado como si de un mapa o un puzle se tratara.
Pero esto no solo se está haciendo con el ser humano. También se ha descifrado el genoma de algunos otros organismos, plantas, animales, bacterias, virus… La cantidad de datos que se generan en este proceso son enormes. Para que nos hagamos una idea, para almacenar la información y la derivada del análisis de los aproximadamente 22.000 genes de una persona, se necesitan cientos de petabytes. Un petabyte 1.024 terabytes y, para que nos hagamos una idea, en un solo petabyte podríamos almacenar más de 65.000 películas en formato 4K, 6,7 millones de discos de música formato MP3 o 500.000 millones de páginas de un archivo de texto.
Todo esto de la investigación en genómica empezó hace ya unas décadas, al principio de manera casi artesanal, hasta llegar a un primer gran hito, con el Human Genome Project. Este proyecto, de carácter público, y en paralelo, con otro de índole privado (Celera Genomics), consiguió secuenciar (leer) completamente el genoma humano en abril de 2003. El desciframiento del genoma humano supuso un esfuerzo de 13 años de investigación y una inversión de 3.000 millones de euros.
big data
Desde entonces, el coste de secuenciación de un genoma humano ha disminuido, considerablemente, como podemos ver en el gráfico (en escala logarítmica) elaborado por Puentes Digitales. Así, mientras que en 2001 este coste era de varios millones de dólares, hoy en día ya se puede hacer por menos de 1.000 $.
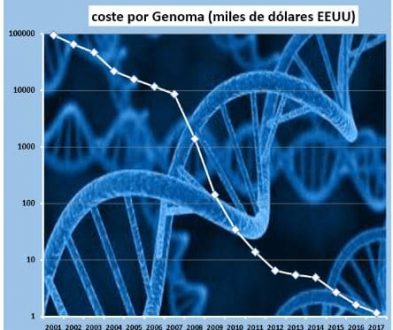
¿Qué tienen que ver estos costes con el big data? Pues que esta bajada de coste ha provocado que cada vez sea más frecuente secuenciar genoma. De hecho, por ejemplo, en Islandia casi 300.000 personas de sus aproximadamente 350.000 habitantes tienen su genoma leído y almacenado en bases de datos. Todo esto significa que cada vez tenemos una cantidad mayor de datos, y que por lo tanto se han de aplicar las técnicas y tecnologías de big data, data mining y data science para tratarlos y obtener información de ellos. Todo esto es esencial para llegar a la medicina personalizada. Gracias a análisis genómicos podremos identificar pacientes de alto riesgo de sufrir una enfermedad, establecer grupos de pacientes dentro de una misma enfermedad, según las alteraciones moleculares (hacer subtipos dentro de las enfermedades) y, finalmente, diseñar tratamientos individualizados, más eficaces y con menos efectos secundarios.
Un ejemplo del uso del big data y todo lo relacionado con él en una investigación genómica lo tenemos en el Consorcio Internacional del Genoma del Cáncer en el que participa España junto a más de 10 países.
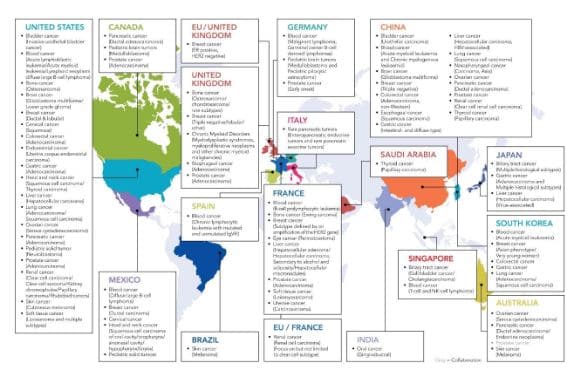
Se trata de un proyecto muy interesante, del que os hablaremos en otro post, en el que se intenta caracterizar cómo es el genoma de cada tipo de cáncer, para así buscar mejor dónde atacar farmacológicamente.
ALZHEIMER Y PARKINSON
En marzo de este mismo año, científicos del Centro de Bioinformática Tropical y Biología Molecular de la Universidad de James Cook (Australia) han realizado un avance en la comprensión de trastornos neurodegenerativos como el Alzheimer y el Parkinson. Se han centrado en el estudio de patrones de fosforilación (una fosforilación es un tipo de modificación química de las proteínas, generalmente sirve para activarlas o inactivarlas) en las sinapsis (zonas de unión entre dos neuronas). Estos fenómenos de fosforilación y desfosforilación son claves en la comunicación entre una neurona y otra y se dan de maneras masiva en las sinapsis. Así, el equipo de investigadores estudió los cambios de fosforilación en varios miles de péptidos y proteínas, lo cual generó una multitud de datos. Obviamente, procesar estos datos no se puede hacer a mano ni con una simple hoja de cálculo. Así que utilizaron técnicas de big data, data mining y data science para estructurar los datos, relacionarlos con las bases de datos ya existentes (de proteínas que fosforilan a otras, denominadas kinasas, de genes, de proteínas en general…), construir así mapas de las rutas de proteínas que las neuronas utilizan para comunicarse entre sí) y también para intentar identificar patrones de actividad relacionados con la memoria.
SANIDAD
En todo lo que rodea a la sanidad hay muchas fuentes de datos que dan lugar a una cantidad tremenda de información. En el sector de la salud se generan desde datos estructurados (aquellos que se pueden almacenar, consultar y manipular de manera automática, como serían los nombres de los pacientes, sus valores analíticos, etc.) hasta datos desestructurados (como las anotaciones médicas, las radiografías, los informes médicos…). Añadamos a esto la gran cantidad de información sobre nuestra salud que generan hoy en día los wearables. Actualmente cada vez hay más personas que portan estos dispositivos digitales durante todo el día. De esta manera, se recopilan datos biométricos casi de manera continua. Estos datos pueden aportar información valiosa al personal sanitario que podría tenerla incluso en tiempo real, haciendo de esa manera un seguimiento exhaustivo al paciente. Puede parecer algo aún no muy cercano, pero algunos de estos dispositivos (o similares) ya se usan en los hospitales, como los pulsioxímetros, para medir la saturación de oxígeno sanguíneo y el pulso cardíaco.
Se estima que la información biomédica de la que se va a disponer se va a multiplicar por dos cada año y medio durante los próximos años. Imaginemos el gran reto que va a suponer su gestión y la obtención de información útil a partir de estos datos (… y el gran negocio que puede haber detrás de ello).
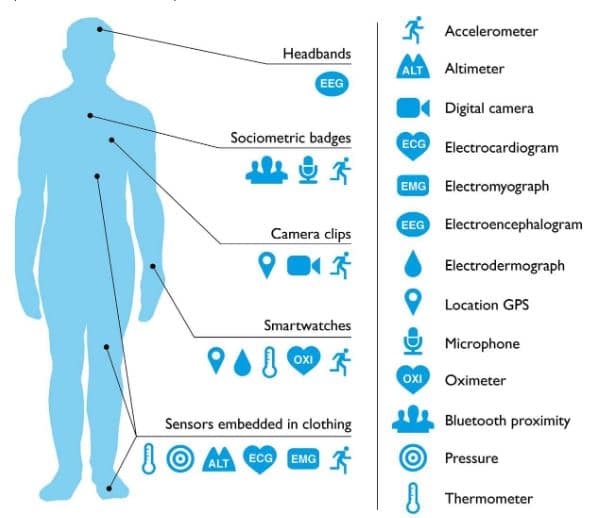
Toda esta enorme cantidad de datos, si es bien tratada, nos puede aportar muchísima información relevante, que se puede utilizar para la prevención de enfermedades y para la personalización de los tratamientos. Además, permitirán un mejor seguimiento de los pacientes crónicos.
Un ejemplo de cómo las técnicas de big data ya están empleando es el caso de la unidad de neonatos del Hospital for Sick Children de Toronto. La infección en niños prematuros es uno de los principales riesgos y preocupaciones para el equipo médico. En 2009 Carolyn McGregor del Instituto de Tecnología de la Universidad de Ontario y el doctor Andrew James buscaron la manera de utilizar los datos que aportan lo monitores a los que están conectados estos niños para predecir el riesgo de infección. Así, en base al ritmo cardíaco y el patrón de respiración desarrollaron algoritmos capaces de predecir infecciones hasta 24 horas antes de que aparezcan los primeros síntomas clínicos. De esta manera se puede realizar una intervención terapéutica prematura y salvar las vidas de un buen número de bebés.
SALUD PÚBLICA
El análisis de datos masivos también se usa para algo que podríamos decir que es lo opuesto de hacer medicina individualizada, pero también muy importante. Así, se utiliza para conocer, predecir y controlar la aparición y evolución de epidemias. Google, por ejemplo, lleva desde 2008 recogiendo información sobre el virus de la gripe en más de 25 países teniendo en cuenta las búsquedas de palabras clave sobre la gripe y comparándolas con otras series de años previos.
Ha habido un caso práctico ya en el que el análisis masivo de datos ha tenido un efecto concreto en un asunto de salud pública. Es el caso del Vioxx. Este medicamento (rofecoxib) es un analgésico y antiinflamatorio no esteroideo (AINE) comercializado por MSD y destinado, fundamentalmente al tratamiento de la artritis. Se trataba de un medicamento muy vendido en todo el mundo hasta que la FDA y Kaiser Permanente (una empresa relacionada con los seguros de salud) descubrieron que la probabilidad de sufrir un ataque al corazón aumentaba de manera alarmante en pacientes que tomaban Vioxx. Según un trabajo publicado en The Lancet en 2005, se estimaba que entre 88.000 y 140.000 casos de cardiopatías graves podían haber sido consecuencia del uso de rofecoxib. Para llegar a estas conclusiones, se empleó el análisis de big data en más de un millón de historias clínicas.
INVESTIGACIÓN EN RED
Las técnicas de big data también pueden a cambiar la manera en que se investiga, potenciando la investigación en red. Así, por ejemplo, el Proyecto Fair4Health. El consorcio Fair4Health quiere contribuir a facilitar y animar a los investigadores en salud a compartir y reutilizar sus conjuntos de datos (datasets), al menos aquellos que están financiados con fondos públicos, mediante la aplicación de los principios FAIR (Findable, Accesible, Interoperable, Reusable). Este proyecto busca demostrar el impacto que la estrategia de los principios FAIR puede tener en la obtención de resultados en la investigación sanitaria. Para ello FAIR4Health aplica técnicas de minería de datos distribuida que preservan la privacidad en los conjuntos de datos compartidos. Concretamente realizarán dos estudios. Uno, para descubrir cuáles son los factores que desencadenan el inicio de una enfermedad, así como posibles patrones de asociación de varias enfermedades. Otro, para crear un servicio de predicción a 30 días del riesgo de reingreso en pacientes crónicos complejos.
DESARROLLO DE FÁRMACOS
Para ver de qué manera el big data y sus técnicas pueden ayudar al desarrollo de los fármacos, lo ver es ver un ejemplo de un proyecto real. El proyecto HARMONY, cuya financiación fue aprobada en 2017 por el programa europeo IMI2 (Iniciativa de Medicamentos Innovadores), dentro del programa Big Data for Better Outcomes (BD4BO). Es un proyecto que pretender acortar el tiempo de desarrollo de un fármaco, desde las etapas iniciales hasta que se llega a la comercialización. Hay que tener en cuenta que para que un fármaco llegue al mercado, desde el momento en que se empieza a investigar sobre esa molécula, pasan, de media, algo más de diez años. A eso hay que sumar que gran parte de las moléculas investigadas no llegan nunca al mercado.
En este proyecto se crea una gran base de datos con registros de hemopatías malignas de más de 50.000 pacientes, donde se recogen datos de evolución, respuesta a fármacos, información de farmacovigilancia, farmacoeconomía y datos de las especialidades denominadas “-ómicas”, es decir, genómica, proteómica, epigenómica… Aaplicando técnicas de big data se va a caracterizar mejor la enfermedad de la que se trate, se pueden buscar marcadores, mejorar el tratamiento… Se busca una repercusión real en el paciente, acortando el tiempo que tarda un fármaco para una enfermedad muy específica en llegar al mercado y también intentando disminuir el coste, tanto para el sistema sanitario como para el paciente.
En este proyecto participan asociaciones de enfermos, hospitales, grupos de investigación, empresas farmacéuticas, de informática… y se trata de uno de los primeros proyectos europeos en el uso de Big Data aplicado a salud.
CERN
El Laboratorio Europeo de Física de Partículas Elementales (CERN), conocido sobre todo por el gran colisionador de hadrones (LHC) situado en la frontera entre Suiza y Francia, es un gran generador de datos de investigación. Su principal objetivo es la búsqueda del origen y constituyentes últimos de la materia. El propio centro cuenta con una impresionante capacidad de cálculo y almacenaje de información, estimada en más de 65.000 procesadores. Sin embargo, ese número de procesadores no es suficiente para analizar la tremenda cantidad de datos que se genera. Así, se estima que cada colisión del LHC produce un petabyte de información por segundo. Dado que es imposible almacenar tantísima información, solo se registra una pequeña proporción de los datos obtenidos, aproximadamente un petabyte cada día. Para poder asimilar toda esta información, se distribuye la capacidad de computación entre miles de ordenadores repartidos entre otros 150 centros de datos de todo el mundo. Se trata quizá del ejemplo más exagerado de una grandísima cantidad de datos generados en un centro de investigación científica y supone todo un reto tecnológico en las áreas del big data y el data mining.

CONCLUSIÓN
Vivimos en una época en la que cada vez medimos más cosas y más veces. Es decir, se genera cada hora, cada minuto, una cantidad increíble de datos. Para que estos datos sean útiles han de convertirse en información. Y ahí es donde entran el big data, el data mining y el data science. La investigación, sea en la rama que sea, y la salud, no son ajenos a esta explosión de datos. Y todos esos datos, bien manejados y gestionados pueden hacer que la investigación progrese de una manera más rápida y eficaz y que la medicina sea también mucho más eficiente, llegando por fin a la tanta veces nombrada medicina personalizada. Pero esta enormidad de datos también presenta una serie de retos, como es la gestión de la privacidad, el almacenamiento y la accesibilidad desde centros remotos.
*Licenciado en farmacia por la Universidad Complutense de Madrid. Realicé mi tesis doctoral en el Departamento de Bioquímica y Biología Molecular de la Facultad de Farmacia. Posteriormente hice un Máster en Dirección de Empresas Biotecnológicas. Trabajé casi un año en una consultoría de biotecnología. Posteriormente fui investigador y docente en la Universidad Complutense de Madrid durante siete años. Mi carrera investigadora se desarrolló en el estudio de los mecanismos moleculares del cáncer (colon y pulmón esencialmente). En noviembre de 2012 abandoné definitivamente el laboratorio. En la actualidad soy titular de una oficina de farmacia.
(Tomado de http://www.dciencia.es/)
El poder de los medicamentos naturales a base de hierbas no se puede sobre enfatizar, Dr.Si eres Dios enviado para curar mi vida, sufriendo cáncer y herpes. Sufrí y grité, Dr.ISE sálvame …, los medicamentos ingleses solo destruyen el mecanismo de mi cuerpo y me causaron más daños …
Hoy en día, mi sistema corporal está completamente libre de enfermedades, estoy fuerte y saludable todo gracias al hogar de Ise Herbal y a la medicina terapéutica natural a base de hierbas. Recomiendo a Dr.Ise como su verdadero y único médico herbolario, probado y confiable,
curó diversas enfermedades en todo el mundo y asociados del Centro para el Control de Enfermedades [CDC] y la Organización Mundial de la Salud [OMS] @ WHATS-APP / CALL +2348151978888 CORREO; ISESPIRITUALSPELLTEMPLE@GMAIL.com O CUREHERBAL633@GMAIL.COM
Jane noelle p.
No veo la relación del comentario de la señora Helen con el contenido del artículo. Tal vez el párrafo en el que el autor comenta como el uso compartido de grandes bases de datos puede reducir el tiempo que tarda un producto, natural o no, en convertirse en un medicamento probado y aplicado con base en la ciencia, haya motivado su testimonio en defensa de la llamada medicina natural o herbolaria. Nadie cuestiona que muchos medicamentos eficaces se han obtenido a partir de plantas. El caso más reciente y muy publicitado fue la introducción de la artemisina, producto obtenido primeramente de la planta Artemisia y que le valió a la Dra. Youyou Tu el Nobel de Medicina con otros dos investigadores. Muchos han querido ver en este justo reconocimiento un espaldarazo al uso de plantas medicinales, pero no es así. La artemisina se convistió en un medicamento solo luego de haber sido identificada y aislada de otros cientos de componentes presentes en la planta original. Caracterizada químicamente, estudida su farmacodinamia y farmacocinética y, sobre todo probada en sus efectos beneficos y adversos en estudios en modelos animales y, finalmente ensayos clínicos controlados, ese fue el largo camino de un producto natural hasta la ciencia. Sustancias como esta pueden abundar en el mundo biológico, pero solo se pueden emplear con seguridad cuando se haya recorrido ese largo camino. Poner su salud en manos de curadores milagrosos y pretendidamente naturales puede ser muy peligroso. He visitado el blog del mencionado Dr. Ise, quien promete que lo cura todo “all illnes” (https://driseherbalcentre.wordpress.com/) y solo encontre allí un testimonio muy semejante al que ofrece la comentarista de una paciente agradecida. Es comprensible que ella y Hellen agradezcan y atribuyan su curación al tratamiento herbolario y yo, sinceramente deseo que conserve por muchos años su buena salud. Pero las enfermedades curan y mejoran por muchas razones, a veces incluso espontáneamente, lo que hace que los testimonios agradecidos tengan en realidad muy poco o ningún valor científico. El Dr. Edzard Ernst (https://edzardernst.com/) recuerda recientemente que junto a estos testimonios hay muchos otros casos en que lamentablemente el abandono o renuncia al tramiento médico condujo a la muerte de personas que, de otro modo se hubieran salvado: Francesco Bonifaz,un niño de 7 años que murió en Italia cuando su médico le recetó homeopatía enlugar de antibioticos; o Mario Rodríguez, quien falleció a los 21 años intentado curar su cáncer con vitaminas; o Jacqueline Alderslade, una mujer de 55 años que murió cuando su homeopata le prohibió utilizar su inhalador para el asma. Gente como Cameron Ayres, un bebé de 6 meses que falleció en Inglaterra por la negativa de sus padres a aplicarle la medicina convencional; o Victoria Waymouth, fallecida a los 57 años bajo tratamiento homeopático para un problema cardiaco; Sofia Balyaykina, rusa de 25 años con un cáncer curable por quimioterapia que prefirió el tratamiento alternativo con picadas de mosquito; y otros muchos. Y el más publicitado, la absurda muerte de Steve Jobs por el tiempo perdido con tratamientos naturales. La medicina científica no lo cura todo, todos los medicamentos tienen efectos adversos, se utilizan tratamientos cruentos en ocasiones, pero es la única esperanza confiable, las alternativas pueden ser muy peligrosas.