

Por Kate O’Neill / Wired
Si utilizas las redes sociales, probablemente hayas notado una tendencia de personas que publican sus imágenes de perfil de hace diez años y ahora. “Yo reflexiono sobre cómo se podrían extraer todos esos datos para entrenar los algoritmos de reconocimiento facial para el análisis de la progresión de la edad y el reconocimiento de la edad”, escribe Kate O’Neill.
En lugar de participar en el #10YearChallenge de Facebook, Instagram y Twitter, en el que las personas publican fotos de hace diez años y ahora, publiqué el siguiente tweet semi-sarcástico:
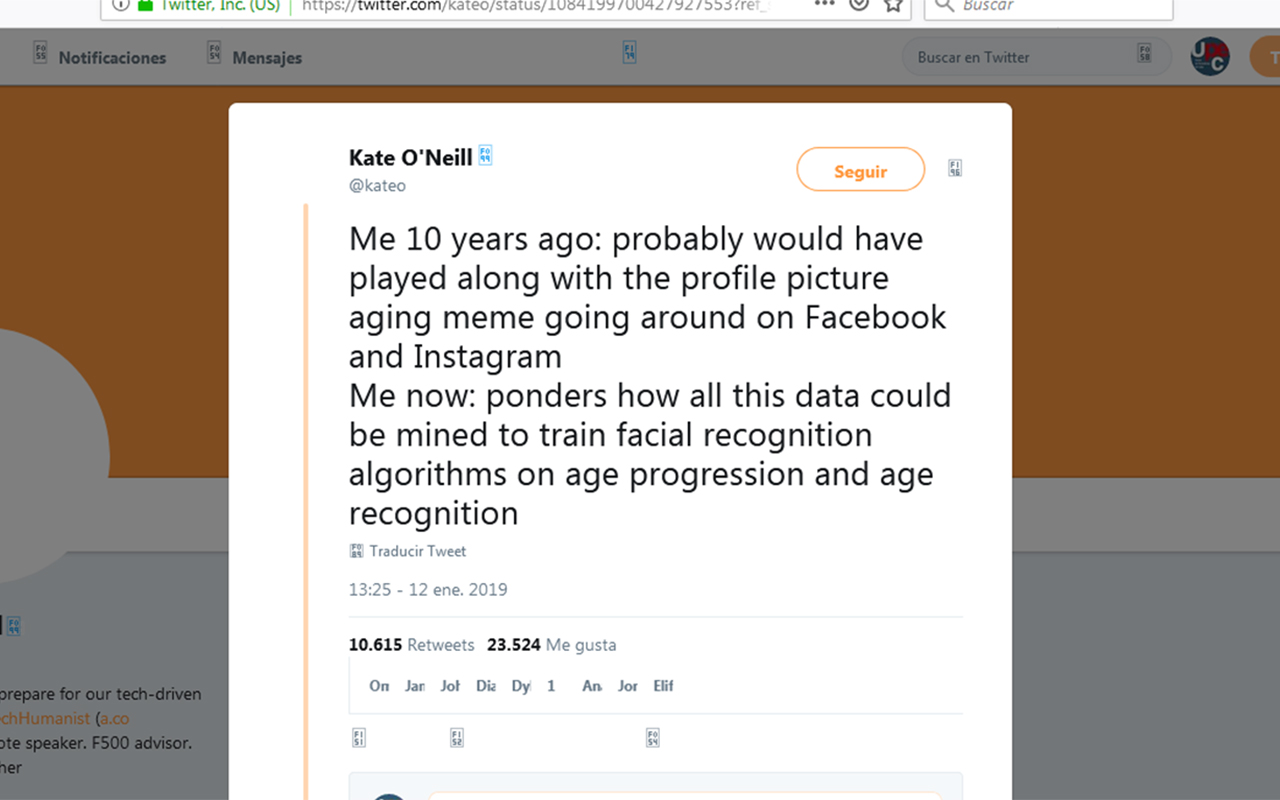
“Yo hace 10 años: probablemente habría jugado con el meme de envejecimiento de la foto de perfil de Facebook e Instagram
Yo ahora: reflexiono sobre cómo se podrían extraer todos esos datos para entrenar los algoritmos de reconocimiento facial para el análisis de la progresión de la edad y el reconocimiento de la edad.”
Mi excitante tweet comenzó a generar polémica. Mi intención no era afirmar que el meme es inherentemente peligroso. Pero sabía que el escenario de reconocimiento facial es ampliamente utilizado y esta evidencia debería ser conocida por la gente. Vale la pena considerar la profundidad y amplitud de los datos personales que compartimos sin reservas.
De los que criticaron mi tesis, muchos argumentaron que las imágenes ya estaban disponibles de todos modos. La refutación más común fue: “Los datos ya están disponibles. Facebook ya tiene todas las fotos de perfil”.
Por supuesto que lo hacen. En varias versiones del meme, las personas recibieron instrucciones de publicar su primera imagen de perfil junto con su imagen de perfil actual, o una imagen de hace 10 años junto con su imagen de perfil actual. Entonces, sí: estas imágenes de perfil existen, tienen registros de tiempo en que se cargó, muchas personas tienen muchas de ellas y, en su mayor parte, son de acceso público.
Pero vamos a poner en práctica esta idea.
Imagine que desea entrenar un algoritmo de reconocimiento facial sobre características relacionadas con la edad y, más específicamente, sobre la progresión de la edad (por ejemplo, cómo es probable que las personas se vean a medida que envejecen). Idealmente, querría un conjunto de datos amplio y riguroso con imágenes de muchas personas. Sería útil si supiera que se tomaron con un número fijo de años, por ejemplo, 10 años.
Claro, puedes buscar en Facebook las fotos de perfil y ver las fechas de publicación o los datos EXIF (se incrustan en el fichero de imagen y contienen información relativa a la propia foto y a cómo ha sido tomada). Pero todo el conjunto de imágenes de perfil podría terminar generando una gran cantidad de ruido inútil. Las personas no cargan las imágenes de forma confiable en orden cronológico, y no es infrecuente que los usuarios publiquen imágenes de otra cosa que no sean ellos mismos como una imagen de perfil. Un vistazo rápido a través de las fotos del perfil de mis amigos de Facebook muestra el perro de un amigo que acaba de morir, varias caricaturas, imágenes de palabras, patrones abstractos y más.
En otras palabras, sería de ayuda si tuviera un conjunto de fotos de antes y ahora, limpio, simple y bien etiquetado.
Además, para las fotos de perfil en Facebook, la fecha de publicación de la foto no coincidiría necesariamente con la fecha en que se tomó la foto. Incluso los metadatos EXIF en la foto no siempre serían confiables para evaluar esa fecha.
¿Por qué? La gente podría haber escaneado fotos sin conexión. Podrían haber subido fotos varias veces durante años. Algunas personas suben capturas de pantalla de imágenes encontradas en otros lugares en línea. Algunas plataformas eliminan los datos EXIF por privacidad.
A través del meme de Facebook, la mayoría de las personas ha estado agregando ese contexto (“yo en 2008 y yo en 2018”), así como más información, en muchos casos, sobre dónde y cómo se tomó la foto (“2008 en la Universidad de lo que sea, tomado por Joe; 2018 visitando la Ciudad de Nueva York para el evento de este año ”.
En otras palabras, gracias a este meme, ahora hay un conjunto de datos muy grande de fotos cuidadosamente seleccionadas de personas de hace aproximadamente 10 años y de ahora.
Por supuesto, no todos los comentarios desdeñosos en mis menciones en Twitter se referían a que las imágenes ya estaban disponibles; algunos críticos señalaron que había demasiados datos de mierda para ser utilizables. Pero los investigadores de datos y los científicos saben cómo filtrar esto. Al igual que con los hashtags que se vuelven virales, generalmente se puede confiar más en la validez de los datos al comienzo de la tendencia o campaña, antes de que las personas comiencen a participar irónicamente o intenten secuestrar el hashtag con propósitos irrelevantes o a repetirlos aburridoramente por cualquier cosa.
En cuanto a las imágenes falsas, los algoritmos de reconocimiento de imágenes son lo suficientemente sofisticados como para elegir un rostro humano. Si subiste una imagen de un gato de hace 10 años y de ahora, como lo hizo uno de mis amigos, adorablemente, esa muestra en particular sería fácil de desechar.
Por su parte, Facebook niega tener una mano en el #10YearChallenge. “Este es un meme generado por el usuario que se volvió viral por sí solo”, respondió un portavoz de Facebook. “Facebook no inició esta tendencia, y el meme usa fotos que ya existen en Facebook. Facebook no gana nada con este meme (además de recordarnos las tendencias de moda cuestionables de 2009). Como recordatorio, los usuarios de Facebook pueden elegir activar el reconocimiento facial y encenderlo o apagarlo en cualquier momento”.
Pero incluso si este meme en particular no es un caso de ingeniería social, los últimos años han estado repletos de ejemplos de juegos sociales y memes diseñados para extraer y recopilar datos. Solo piense en la extracción masiva de datos de más de 70 millones de usuarios de Facebook en EEUU realizada por Cambridge Analytica.
¿Es malo que alguien pueda usar tus fotos de Facebook para entrenar un algoritmo de reconocimiento facial? No necesariamente; en cierto modo, es inevitable. Sin embargo, lo más amplio aquí es que tenemos que enfocarnos en nuestras interacciones con la tecnología teniendo en cuenta los datos que generamos y cómo se puede usar a escala. Ofreceré tres casos de uso plausibles para el reconocimiento facial: uno respetable, uno cotidiano y otro arriesgado.
El escenario benigno: la tecnología de reconocimiento facial, específicamente la capacidad de progresión de la edad, podría ayudar a encontrar niños desaparecidos. El año pasado, la policía de Nueva Delhi informó que había rastreado a casi 3000 niños desaparecidos en solo cuatro días usando tecnología de reconocimiento facial. Si los niños desaparecen por un tiempo, probablemente se verían un poco diferentes de la última foto conocida de ellos, por lo que un algoritmo confiable de progresión de la edad podría ser realmente útil aquí.
El potencial del reconocimiento facial es en su mayoría cotidiano: el reconocimiento de la edad es probablemente más útil para la publicidad dirigida. Las pantallas de anuncios que incorporan cámaras o sensores y pueden adaptar sus mensajes a la demografía del grupo de edad (así como a otras características reconocibles visualmente y contextos perceptibles) probablemente serán comunes en poco tiempo. Esa aplicación no es muy emocionante, pero puede hacer que la publicidad sea más relevante. Pero a medida que la información fluye y se entreteje con el seguimiento de nuestra ubicación, respuestas, comportamientos de compra y otras señales, podría provocar algunas interacciones realmente espeluznantes.
Como la mayoría de las tecnologías emergentes, existe la posibilidad de consecuencias difíciles. La progresión de la edad podría algún día influir en la evaluación para otorgar seguros y atención médica. Por ejemplo, si parece estar envejeciendo más rápido que sus cohortes, quizás no sea un muy buen riesgo para pagar un seguro. Puede que tenga que pagar más o se le puede negar la cobertura.
Después de que Amazon introdujera los servicios de reconocimiento facial en tiempo real a finales de 2016, comenzaron a venderlos a las agencias policiales y gubernamentales, como los departamentos de policía en Orlando y el Condado de Washington, Oregón. Pero la tecnología plantea mayores preocupaciones de privacidad; la policía podría usar la tecnología no solo para rastrear a las personas sospechosas de haber cometido delitos, sino también a las personas que no están cometiendo delitos, como los manifestantes y otros a quienes la policía considera una molestia.
La American Civil Liberties Union le pidió a Amazon que dejara de vender este servicio. Lo mismo hicieron una parte de los accionistas y empleados de Amazon, quienes solicitaron a Amazon que lo suspendiera, citando preocupaciones por la valoración y reputación de la compañía.
Es difícil exagerar la plenitud de cómo la tecnología puede impactar a la humanidad. Existe la oportunidad para que la mejoremos, pero para hacerlo también debemos reconocer algunas de las formas en que puede empeorar. Una vez que entendamos los problemas, necesitamos una balanza.
Entonces, ¿esto es tan importante? ¿Ocurrirán cosas malas porque publicaste en tu muro algunas fotos de perfil que ya son públicas? ¿Es peligroso entrenar algoritmos de reconocimiento facial para la progresión de la edad y el reconocimiento de la edad? No exactamente.
Independientemente del origen o la intención detrás de este meme, todos debemos ser más conocedores de los datos que creamos y compartimos, el acceso que le otorgamos y las implicaciones para su uso. Si el contexto era un juego que expresaba explícitamente que estaba recolectando pares de fotos de entonces y ahora para la investigación de la progresión de la edad, podría optar por participar con la conciencia de quién debía tener acceso a las fotos y con qué propósito.
El mensaje más amplio, eliminado de los detalles específicos de cualquier meme o incluso de cualquier plataforma social, es que los humanos son las fuentes de datos más ricas para la mayoría de la tecnología emergente en el mundo. Debemos saber esto, y proceder con la debida diligencia y sofisticación.
Los seres humanos son el enlace conectivo entre el mundo físico y el digital. Las interacciones humanas son la mayoría de lo que hace que el Internet de las cosas sea interesante. Nuestros datos son el combustible que hace que las empresas sean más inteligentes y ganen más dinero.
Debemos exigir que las empresas traten nuestros datos con el debido respeto, por todos los medios. Pero también debemos tratar nuestros propios datos con respeto.
Kate O’Neill es la fundadora de KO Insights y autora de Tech Humanist y Pixels and Place: Connecting Human Experience Across Physical and Digital Spaces.
(Tomado de Dominio Cuba)